کتابخانه Seaborn برای مصورسازی داده در پایتون: بخش اول
مقدمه
Seaborn را در این مقاله مورد توجه قرار می دهیم که یک کتابخانه بسیار مفید مصورسازی داده در پایتون محسوب می گردد. کتابخانه Seaborn روی Matplotlib ساخته می شود و قابلیت های پیشرفته بسیاری در رابطه با مصورسازی داده ارائه می کند.
گرچه، کتابخانه Seaborn را جهت رسم انواع چارت هایی چون نمودارهای ماتریسی، نمودارهای شبکه ای (Grid)، نمودارهای رگرسیونی و غیره می توان مورد استفاده قرار داد، در این مقاله، نحوه استفاده از کتابخانه Seaborn برای رسم نمودارهای توزیعی را مورد بررسی قرار خواهیم داد. نحوه رسم نمودارهای دسته ای(categorical)، نمودارهای رگرسیونی، نمودارهای ماتریسی و نمودارهای شبکه ای، در بخش های بعدی این سری مورد توجه قرار خواهد گرفت.
دانلود کتابخانه Sesborn
کتابخانه Seaborn را به دو طریق می توان دانلود کرد. چنانچه از نصب کننده پیپ (pip Installer) برای کتابخانه های پایتون استفاده میکنید، فرمان زیر را برای دانلود این کتابخانه می توانید اجرا کنید:
pip install seaborn
در غیر اینصورت، چنانچه از توزیع Anaconda پایتون استفاده می کنید، فرمان زیر را جهت دانلود کتابخانه Seaborn می توانید اجرا نمایید:
conda install seaborn
دیتاست
دیتاست Titanic، دیتاستی است که ما قصد داریم جهت رسم نمودارهایمان مورد استفاده قرار دهیم که به صورت پیش فرض با استفاده از کتابخانه Seaborn دانلود می شود. استفاده از تابع load_dataset و ارسال نام دیتاست به آن، تنها کاری است که باید انجام دهید.
حال بیایید ببینیم دیتاست Titanic حاوی چه اطلاعاتی است. اسکریپت زیر را اجرا نمایید:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset = sns.load_dataset('titanic')
dataset.head()
اسکریپت قسمت بالا، دیتاست Titanic را بارگیری می کند و پنج سطر نخست این دیتاست را با استفاده از تابع head نمایش می دهد. خروجی، چیزی شبیه مورد زیر میشود:

این دیتاست شامل 891 سطر و 15 ستون و حاوی اطلاعاتی در رابطه با مسافرانی است که سوار کشتی شوم Titanic شدند. پیش بینی این امر که آیا مسافران بسته به ویژگی های مختلفی چون سن، بلیط، کابینی که سوار شدند، کلاس بلیط و غیره جان سالم بدر بردند یا نه، کار اصلی و اولیه ماست. از کتابخانه Seaborn استفاده خواهیم کرد تا ببینیم آیا الگویی در این داده ها می توان یافت.
نمودارهای توزیعی
نمودارهای توزیعی، همان طور که از نامشان پیداست، نوعی از نمودارها هستند که توزیع آماری داده ها را نشان می دهند. برخی از متداول ترین نمودارهای توزیعی در Seaborn را در این بخش بررسی خواهیم کرد.
نمودار توزیعی (Dist Plot)
Distplot، هیستوگرام داده های یک ستون را نشان می دهد. نام ستون به عنوان یک پارامتر، به تابع Distplot ارسال می شود. حال بیابید نحوه توزیع قیمت بلیط هر مسافر را بررسی نماییم. اسکریپت زیر را اجرا نمایید:
sns.distplot(dataset['fare'])
خروجی:
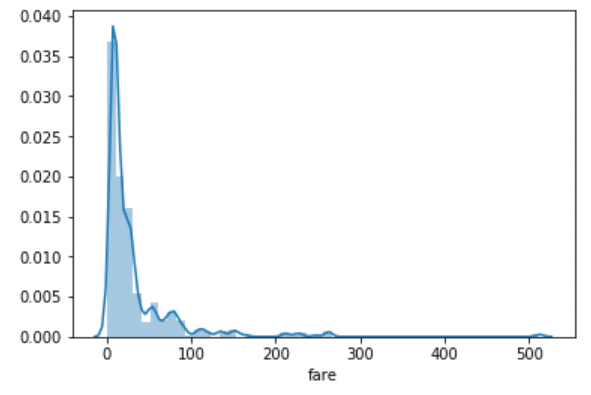
شما می توانید مشاهده کنید که اکثر بلیط ها، بین 50-0 دلار فروخته شده اند. خطی که مشاهده می کنید برآورد چگالی کرنل را نشان می دهد. این خط را با ارسال False به عنوان پارامتر kde، همان گونه که در قسمت زیر نشان داده می شود، می توان حذف کرد:
sns.distplot(dataset['fare'], kde=False)
خروجی:
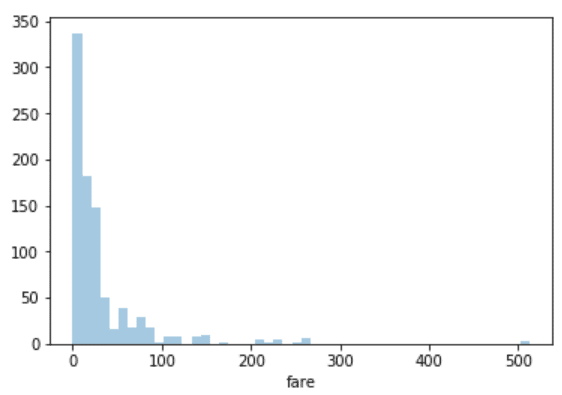
حال مشاهده می کنید که خطی برای برآورد چگالی کرنل در این نمودار وجود ندارد. شما می توانید با ارسال مقدار برای پارامتر bins، جزئیات کمتر یا بیشتری را در نمودار مشاهده نمایید. نگاهی به اسکریپت زیر بیندازید:
sns.distplot(dataset['fare'], kde=False, bins=10)
تعداد bins، در این قسمت، 10 تنظیم می گردد، داده های توزیع شده در 10 بین (bin) را همان طور که در قسمت زیر نشان داده می شود، مشاهده خواهید کرد:
خروجی:
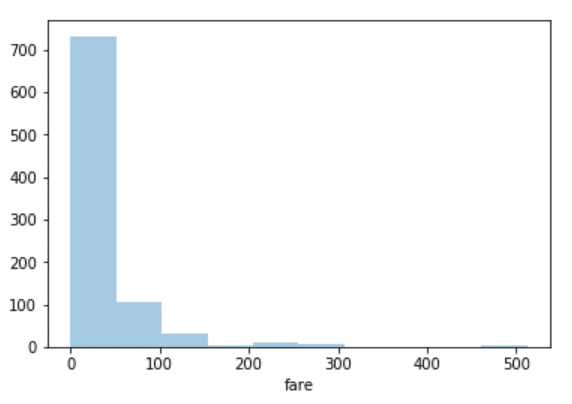
شما به وضوح مشاهده می کنید که قیمت بلیط بیش از 700 مسافر، بین 0 و 50 دلار است.
نمودار مشترک (joint Plot)
Jointplot، جهت نمایش توزیع متقابل (مشترک) هر ستون بکار می برد. شما باید سه پارامتر را به jointplot ارسال نمایید. نام ستونی که میخواهید توزیع داده های آن روی محور x نمایش داده شود، پارامتر نخست را تشکیل می دهد. پارامتر دوم، نام ستونی است که توزیع داده های آن در محور y نمایش داده میشود. دست آخر اینکه دیتافریمی که دادگان در آن هستند، پارامتر سوم به حساب می آید.
حالا بیایید یک نمودار مشترک بین ستون های سن (age) و کرایه (fare) را رسم کنیم تا ببینیم آیا هیچ گونه رابطه ای میان این دو می توان یافت.
sns.jointplot(x='age', y='fare', data=dataset)
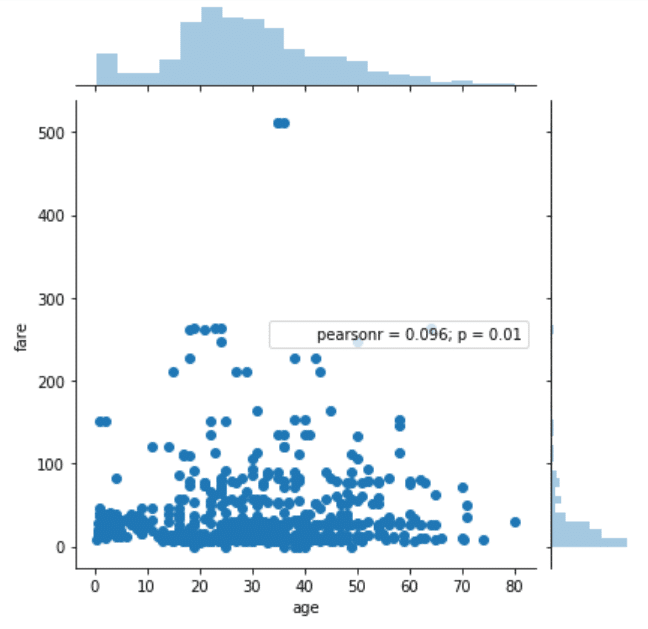
با توجه به خروجی می توان دریافت که یک نمودار مشترک، سه بخش دارد. یک نمودار توزیعی در بالا برای دادهای محور x، یک نمودار توزیعی در سمت راست برای دادهای محور y و یک نمودار پراکندگی یا نمودار نقاط پراکنده (Scatter Plot) در این میان، که توزیع متقابل داده های هر دو ستون را نشان می دهد. شما می توانید ببینید که هیچ همبستگی میان سن و کرایه ها مشاهده نشد.
نوع نمودار مشترک را به واسطه ی ارسال یک مقدار برای پارامتر kind می توانید تغییر دهید. برای نمونه، چنانچه به جای نمودار پراکندگی، خواهان نمایش توزیع داده به شکل یک نمودار شش ضلعی (Hexagonal Plot) باشید، می توانید مقدار hex را برای پرامتر kind ارسال نمایید. اسکریپت زیر را ببینید:
sns.jointplot(x='age', y='fare', data=dataset, kind='hex')
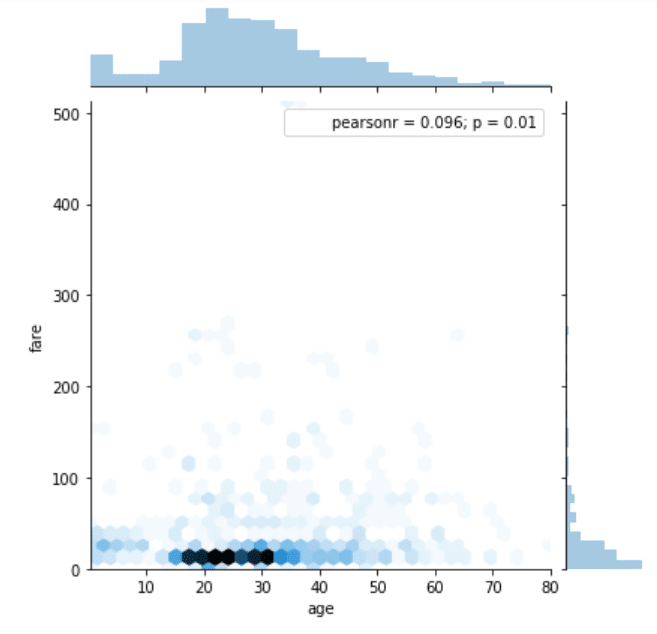
شش ضلعی با بیشترین تعداد نقطه در نمودار شش ضلعی، رنگ تیره تری پیدا میکند. لذا، اگر نگاهی به نمودار بیندازید، در می یابید که اکثر مسافران، بین 20 و 30 سال دارند و اکثریت شان، بین 50- 10 دلار برای بلیط پرداخت کردند.
نمودار جفتی (Pair Plot)
Pairplot، نوعی نمودار توزیعی است که اساساً به رسم یک نمودار مشترک برای کلیه ی ترکیبات ممکن ستون های عددی و بولی (Boolean) در دیتاست شما می پردازد. شما فقط باید دیتافریم خود را به عنوان پارامتر، همان طور که در قسمت زیر نشان داده می شود، به تابع Pairplot ارسال نمایید:
sns.pairplot(dataset)
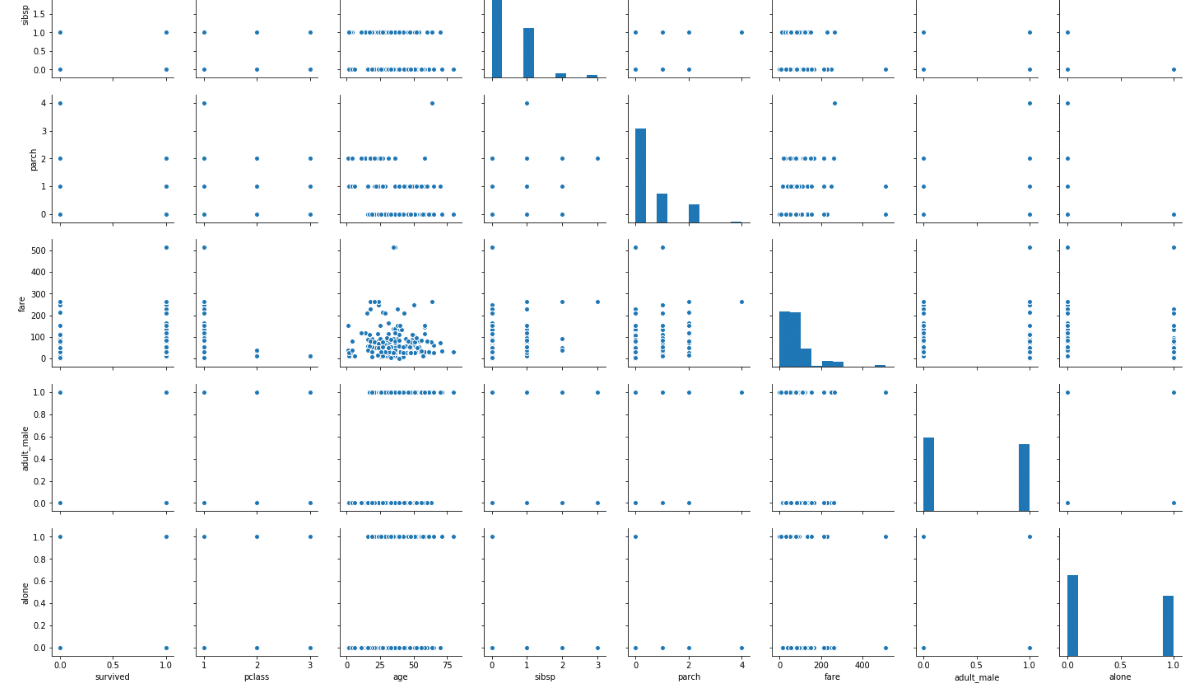
نکته: پیش از اجرای اسکریپت بالا، کلیه ی مقادیر تهی (Null Values) را با استفاده از فرمان زیر، از دادگان حذف کنید:
dataset = dataset.dropna()
نمودارهای مشترک کلیه ی ستون های عددی و بولی در دیتاست Titanic را در خروجی نمودار جفتی میتوان مشاهده نمود.
شما، جهت افزودن اطلاعات ستون دسته ای (categorical) به نمودار جفتی، نام ستون دسته ای را به پارامتر hue بدهید. برای نمونه، چنانچه خواهان رسم اطلاعات جنسیتی روی نمودار جفتی هستید، اسکریپت زیر را میتوانید اجرا نمایید:
sns.pairplot(dataset, hue='sex')

اطلاعات مربوط به افراد مذکر با رنگ نارنجی و اطلاعات مربوط به افراد مونث با رنگ آبی (همان گونه که در شرح علائم و اختصارات نشان داده شده) در خروجی قابل مشاهده است. این امر را که اکثریت مسافران نجات یافته، مونث هستند در نمودار مشترک واقع در قسمت بالای سمت چپ، به روشنی دیده میشود.
نمودار Rug
Rugplot، نموداری است که برای مصورسازی داده های کیفی تک بعدی به صورت خط هایی روی یک محور استفاده میشود. از آن برای نمایش نحوه توزیع داده ها استفاده میشود؛ شاید بتوان آن را به هیستوگرامی با بازه هایی (bin) با طول صفر تشابه کرد. از این نمودار معمولا به همراه نمودارهای دیگه مانند scatter plot استفاده میشود. برای رسم یک نمودار Rug، باید داده های یک ستون (Series) را به تابع بدهید. حال بیایید یک نمودار Rug برای کرایه رسم کنیم.
sns.rugplot(dataset['fare'])
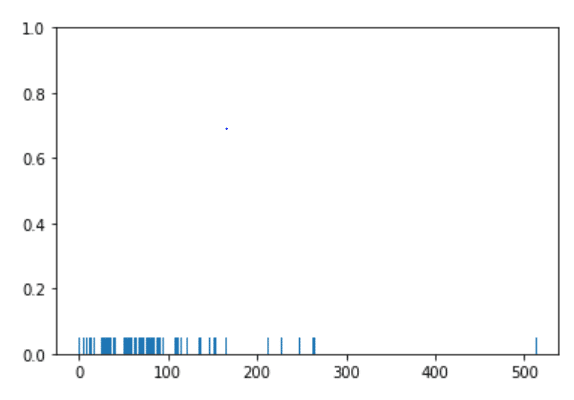
با توجه به خروجی می توان دریافت که همچون مورد distplot، اکثر نمونه های کرایه ها دارای مقادیر بین 0 و 100 هستند.
این مطلب ادامه دارد …