ساده ترین راه پیشگیری از بیش برازش (Overfitting) کدام است؟
تکنیک حذف تصادفی (Dropout)، آن طور که من دریافتم، یک تکنیک پیچیده اما کاربردی است. اصطلاح «حذف تصادفی» به تکنیکی اطلاق می شود که برخی گره های(node) شبکه را به صورت تصادفی حذف می کند. حذف تصادفی را می توان به صورت غیرفعال سازی موقت یا نادیده گیری نورون های شبکه درنظر گرفت. این تکنیک در فاز آموزش، جهت کاهش بیش برازش بکار می رود.
بیش برازش چیست؟
بیش برازش(Overfitting)، به حالی گفته میشود که شبکه عصبی شما کاملا به داده های آموزش شما برازش میشود(خطا پایین است) و در دادهای تست خطای بالایی دارد یا به عبارتی دیگر با دادهایی که تابحال ندیده است بد کار میکند.
در فرایند یادگیری وقتی مدل بیش برازش میشود، رفتار آن به نحوی است که دادگان را در حافظه ذخیره می کند (Memorize) و و این ذخیره سازی حامل نویزی است که عدم توانایی پیش بینی در آینده را نتیجه می دهد. یک شبکه کاملا متصل(fully connected layer)، از همه نودها استفاده میکند و از این رو، نورون ها، هم وابستگی (Co-dependency) را در میان یکدیگر در طول آموزش توسعه می دهند که قدرت خاص هر نورون را محدود می سازد و به بیش برازش دادگان آموزش منتهی می گردد.
تعریف حذف تصادفی
حال بیایید ببینیم مردم عادی چه درکی از این تکنیک دارند. این طور فرض کنید که هر روز با تعداد زیادی از افراد ملاقات می کنید. درحالی که شخصا با آن ها صحبت می کنید، چهره را به خاطر می سپرید. گاهی اوقات ارتباط شما به اجبار تلفنی است. همان افراد را این بار تشخیص نمی دهید، چون آن ها را فقط دیده اید و چهره شان را به یاد دارید. شما، در ارتباط تلفنی صدایشان را به خاطر می سپارید و به یاد می آورید. بنابراین، شما، با حذف تصادفی ویژگی های بصری، مجبور می شوید روی ویژگی های صوتی تمرکز نمایید.
رگولاریزاسیون(regularization)، در یادگیری ماشین، راهی برای پیشگیری از بیش برازش به حساب می آید. رگولاریزاسیون، بیش برازش را از طریق افزودن جریمه (Penalty) به تابع زیان (Loss Function) کاهش می دهد. حذف تصادفی، تکنیکی برای رگولاریزاسیون در شبکه های عصبی است. هنگامی که گره های خاص را به صورت تصادفی حذف می کنید، این واحدها، در طول یک مرور رو به جلو (Forward Pass) یا یک مرور رو به عقب(Backward Pass) در یک شبکه درنظر گرفته نمی شوند.
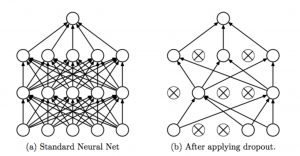
حذف تصادفی، همان طور که در شکل قسمت بالا نشان داده شد، برخی نورون های شبکه های عصبی را به صورت تصادفی غیرفعال(Mute) می کند. هریک از گره ها در هر مرحله آموزش، یا با احتمال 1-p به صورت تصادفی حذف می گردند یا با احتمال p حفظ می گردند، لذا، اندازه کلی شبکه کاهش پیدا می کند. لبه های ورودی و خروجی (Incoming and Outgoing Edges) یک گره حذف شده(droped) نیز حذف می شود. میزان احتمال p حذف کردن نورون ها، اغلب معمولا ۰.۵ تعیین می شود، زمانی که p برابر ۱ باشد، هیچ نورونی حذف نمی شود.

چگونه حذف تصادفی از بیش برازش پیشگیری می کند؟
حذف تصادفی، یک شبکه عصبی را مجبور می کند تا ویژگی های مفید(Robust) بیشتری را یاد بگیرد که به همراه بسیاری از زیرمجموعه های تصادفی مختلف از سایر نورون ها، سودمند هستند. این امر، اوزان را به جای تمرکز فقط بر داده های ورودی، به کل ویژگی های داده های ورودی پخش می کند.
نتیجه گیری
اگر شبکه شما، بیش برازش قابل توجه ای دارد، حذف تصادفی، تعداد زیادی از خطاهای شما را کاهش خواهد داد. حذف تصادفی، تعداد تکرارهای مورد نیاز برای همگرایی را تقریبا دو برابر می سازد، ولی زمان آموزش هر دوره را کاهش می دهد. حذف تصادفی، در Denoising Autoencoders توسعه یافته توسط پاسکال وینسنت (Pascal Vincent)، هوگو لاروچلو (Hugo Larochelle) و یوشوا بنجیو (Yoshua Bengio)، در لایه ورودی بکار رفت. به همین ترتیب، Object Recognition Net توسعه یافته توسط الکس کریژوسکی (Alex Krizhevsky) نیز این تکنیک را مورد استفاده قرار می دهد.
دریافت مقاله اصلی Dropout: A Simple Way to Prevent Neural Networks from Overfitting