کتابخانه Seaborn برای مصورسازی داده در پایتون: بخش سوم
کتابخانه Seaborn را در این مقاله مورد توجه قرار می دهیم که یک کتابخانه بسیار مفید مصورسازی داده در پایتون محسوب می گردد. کتابخانه Seaborn روی Matplotlib ساخته می شود و قابلیت های پیشرفته بسیاری در رابطه با مصورسازی داده ارائه می کند.
در مقاله اول نحوه استفاده از کتابخانه Seaborn برای رسم نمودارهای توزیعی و در مقاله دوم نحوه رسم نمودارهای دسته ای(categorical) را مورد بررسی قرار دادیم. در این مقاله نحوه رسممودارهای رگرسیونی، نمودارهای ماتریسی و نمودارهای شبکه ای مورد توجه قرار خواهد گرفت.
نمودارهای ماتریسی (Matrix Plot)
نمودارهای ماتریسی، نوعی از نمودارها هستند که داده ها را به شکل سطرها و ستون ها نشان می دهند. نقشه های حرارتی (Heat Maps)، نمونه های اولیه نمودارهای ماتریسی محسوب می گردند.
نقشه های حرارتی (Heat Maps)
نقشه های حرارتی، معمولاً برای رسم نمودار همبستگی میان ستون های عددی به صورت ماتریس مورد استفاده قرار می گیرند. ذکر این نکته در اینجا حائز اهمیت است که رسم نمودارهای ماتریسی مستلزم داشتن اطلاعات معنی دار در مورد سطرها و همچنین ستون هاست. حال اجازه دهید پنج سطر نخست دادگان Titaninc مقاله قبلی را مشاهده کنیم. اسکریپت زیر را اجرا نمایید:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset = sns.load_dataset('titanic')
dataset.head()
با توجه به خروجی می توان دریافت که ستون ها حاوی اطلاعات مفید همچون مسافران زنده مانده، سن آن ها، کرایه و غیره است. اما سطرها تنها شاخص های 0، 1، 2 و غیره را در برمی گیرد. رسم نمودارهای ماتریسی نیازمند اطلاعات مفید در خصوص عنوان ستون ها و عنوان سطرها است. استفاده از تابع corr روی دادگان، یک راه انجام این کار است. تابع corr، همبستگی میان کلیه ی ستون های عددی دادگان را محاسبه میکند. اسکریپت زیر را اجرا کنید:
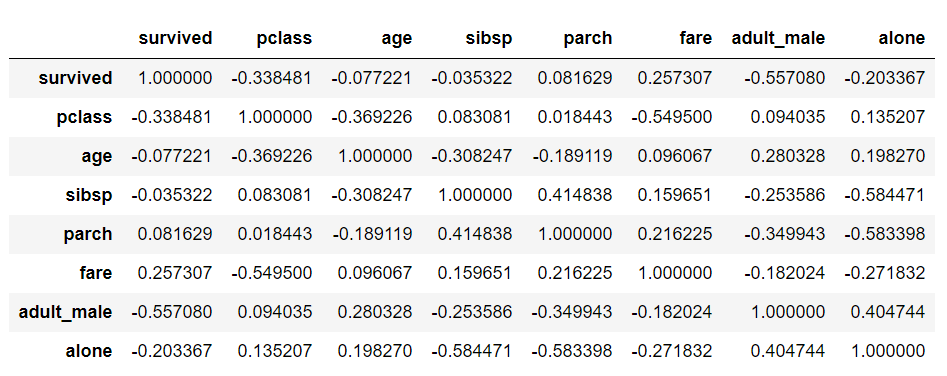
dataset.corr()
با توجه به خروجی درخواهید یافت که هم ستون ها و هم سطرها دارای اطلاعات معنی دار هستند که در قسمت زیر نشان داده می شود:
اکنون، ایجاد یک نقشه حرارتی با استفاده از مقادیر همبستگی، نیازمند فراخواندن تابع heatmap و ارسال دیتافریم حاوی مقادیر همبستگی به آن است. اسکریپت زیر را در نظر بگیرید:
corr = dataset.corr() sns.heatmap(corr)
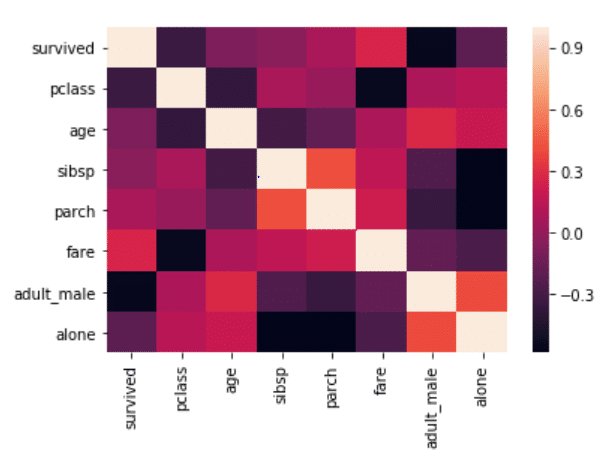
نظر به خروجی می توان دریافت که رسم یک جعبه برای هر ترکیب سطرها و ستون ها، در اصل کاری است که نقشه حرارتی انجام می دهد. رنگ جعبه، به مقدار آن خانه بستگی دارد. مثلاً در عکس بالا، چنانچه همبستگی بالایی میان دو ویژگی وجود داشته باشد، خانه یا جعبه متناظر، سفید است، از طرف دیگر، چنانچه همبستگی وجود نداشته باشد، خانه متناظر، سیاه باقی می ماند. این طیف رنگی از کمترین مقدار تا بیشترین مقدار تمام خانه های ماتریس تغییر میکند که در سمت راست جدول قابل مشاهده است.
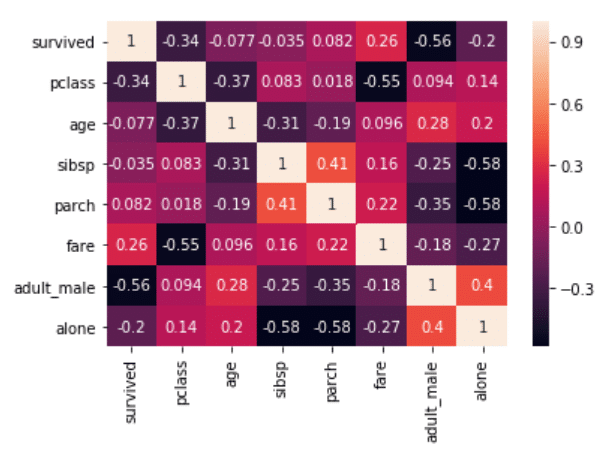
مقادیر همبستگی را نیز، از طریق ارسال True برای پارامتر annot در نقشه حرارتی می توان مشاهده نمود. اسکریپت زیر را جهت مشاهده عملکرد این امر اجرا نمایید:
corr = dataset.corr() sns.heatmap(corr, annot=True)
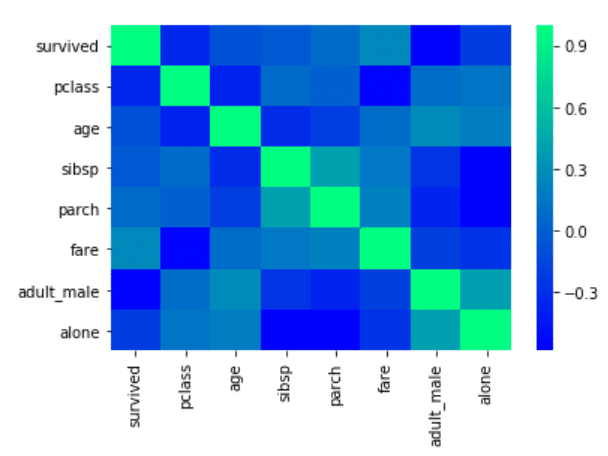
رنگ نقشه حرارتی را نیز از طریق ارسال یک ورودی برای پارامتر cmap می توان تغییر داد. نگاهی به اسکریپت زیر داشته باشید:
corr = dataset.corr() sns.heatmap(corr, cmap='winter')
شما، علاوه بر استفاده از همبستگی میان کلیه ی ستون ها، می توانید از تابع pivot_table برای تبدیل دادگان به ساختار مناسب استفاده نمایید. دادگان “flights” را جهت مشاهده عملکرد تابع pivot_table مورد استفاده قرار خواهیم داد که حاوی اطلاعات مربوط به سال، ماه و تعداد مسافرانی است که در آن ماه مسافرت داشتند.
اسکریپت زیر را جهت وارد کردن دادگان و مشاهده پنج سطر نخست اجرا نمایید:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset = sns.load_dataset('flights')
dataset.head()
حال با استفاده از تابع pivot_table، دادگان را ساختاری تبدیل میکنیم که در آن اندیس سطرها را ماه های سال و ستون های آنر را سال های موجود در ستون year تشکیل میدهد که مقدار هر خانه از ستون passengers تامین میشود. سپس یک نقشه حرارتی ایجاد می کنیم که تعداد مسافرانی را نمایش می دهد که در یک ماه خاص از یک سال مسافرت داشتند. ما، به منظور انجام این کار، month را به عنوان مقدار برای پارامتر index ارسال می کنیم. آنگاه، year را به عنوان مقدار برای پارامتر column باید ارسال نماییم. و دست آخر اینکه، ستون passengers را برای پارامتر values ارسال خواهیم کرد. اسکریپت زیر را اجرا نمایید:
data = dataset.pivot_table(index='month', columns='year', values='passengers') sns.heatmap(data)
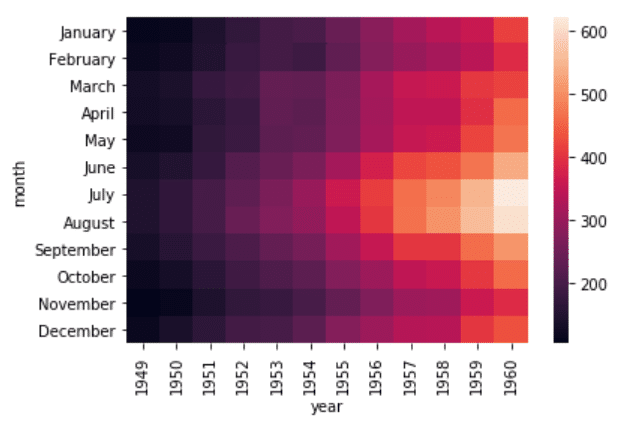
خروجی به روشنی نشان می دهد که تعداد مسافران این پروازها در سال های آغازین، کمتر بوده. تعداد مسافران، با گذشت سال ها افزایش پیدا می کند.
همانطور که مشاهده می کنید جعبه ها یا خانه ها، در برخی موارد، همپوشانی دارند و میان مرزهای خانه ها، خیلی مشخص نیست. پارامترهای linecolor و linewidths را جهت ایجاد یک مرز مشخص می توانید مورد استفاده قرار دهید. نگاهی به اسکریپت زیر داشته باشید:
data = dataset.pivot_table(index='month', columns='year', values='passengers' ) sns.heatmap(data, linecolor='blue', linewidth=1)
ما، در اسکریپت بالا، “blue” را به عنوان مقدار برای پارامتر linecolor ارسال می کنیم، در حالی که، پارامتر linewidth، 1 تعیین می گردد. یک مرز آبی پیرامون هر خانه را در خروجی مشاهده خواهید کرد:
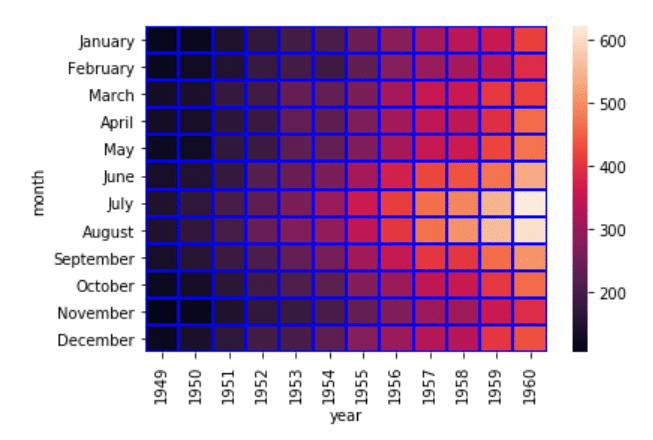
چنانچه خواهان مرزهای ضخیم تر باشید، می توانید مقدار linewidth را افزایش دهید.
نقشه خوشه ای (Cluster Map)
نقشه خوشه ای، همچون نقشه حرارتی، دیگر نمودار ماتریسی پرکاربرد محسوب می گردد. نقشه خوشه ای، اساساً خوشه بندی سلسله مراتبی (Hierarchical Clustering) را جهت خوشه بندی سطرها و ستون های ماتریس بکار می برد.
حال بیایید یک نقشه خوشه ای برای تعداد مسافرانی رسم کنیم که در یک ماه خاص از یک سال خاص مسافرت داشتند. اسکریپت زیر را اجرا نمایید:
data = dataset.pivot_table(index='month', columns='year', values='passengers') sns.clustermap(data)
تابع clustermap جهت رسم نقشه خوشه ای مورد استفاده قرار می گیرد و دادگان ارسال شده، همچون تابع نقشه حرارتی، باید از سطرها و هم ستون ها معنادار برخوردار باشد. خروجی اسکریپت بالا، چیزی شبیه مورد زیر است:

ماه ها و سال های با هم خوشه بندی شده بر اساس تعداد مسافرانی که در یک ماه خاص سفر داشتند را در خروجی می توان مشاهده کرد.
بحث ما پیرامون نمودارهای ماتریسی، با این خروجی، خاتمه پیدا می کند. بحث در خصوص قابلیتهای شبکه ای (Grid) کتابخانه Seaborn را در بخش بعد آغاز خواهیم کرد.
شبکه های Seaborn
شبکه ها در Seaborn، امکان دستکاری نمودارهای فرعی یا زیرنمودارها (Subplot) را بسته به ویژگی های مورد استفاده در نمودارها، برای ما فراهم می سازند.
شبکه جفتی (Pair Grid)
نحوه استفاده از نمودار جفتی برای رسم نمودار پراکندگی کلیه ی ترکیبات ممکن ستون های عددی در دادگان را در بخش اول این سری مقالات مورد بررسی قرار دادیم.
حال بیایید، پیش از آنکه به سراغ شبکه جفتی برویم، مروری بر نمودار جفتی داشته باشیم. دادگان “iris”، دادگانی است که برای بخش شبکه جفتی می خواهیم مورد استفاده قرار دهیم، این دادگان، به صورت پیش فرض در زمان دانلود کتابخانه seaborn، دانلود می شود. اسکریپت زیر را برای بارگیری دادگان iris اجرا نمایید:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset = sns.load_dataset('iris')
dataset.head()
اکنون بیایید یک نمودار جفتی بر اساس دادگان iris رسم کنیم. اسکریپت زیر را اجرا نمایید:
sns.pairplot(dataset)
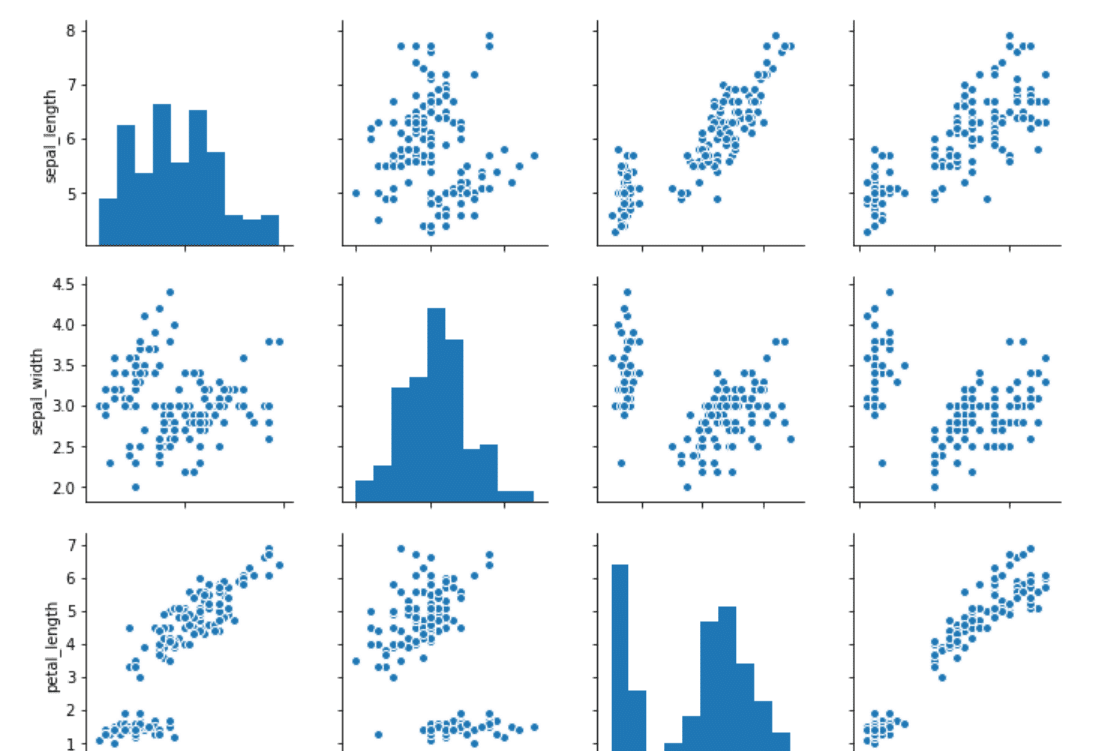
اینک بیایید شبکه جفتی را رسم کنیم و تفاوت میان نمودار جفتی و شبکه جفتی را مورد بررسی قرار دهیم. شما، جهت ایجاد یک شبکه جفتی، صرفاً باید دادگان را به تابع PairGrid، همان طور که در قسمت زیر نشان داده می شود، ارسال نمایید:
sns.PairGrid(dataset)

شبکه های خالی را در خروجی می توانید مشاهده نمایید. این کار، در اصل کاری است که تابع شبکه جفتی انجام می دهد. یک مجموعه خالی را برای کلیه ویژگی های موجود در دادگان باز می گرداند.
آنگاه، تابع map در شی (object) بازگردانده شده به واسطه ی تابع شبکه جفتی را باید فراخوانید و نوع نموداری را که می خواهید در شبکه ها رسم کنید، به آن ارسال نمایید. حال بیایید یک نمودار پراکندگی را با استفاده از شبکه جفتی رسم کنیم.
grids = sns.PairGrid(dataset) grids.map(plt.scatter)
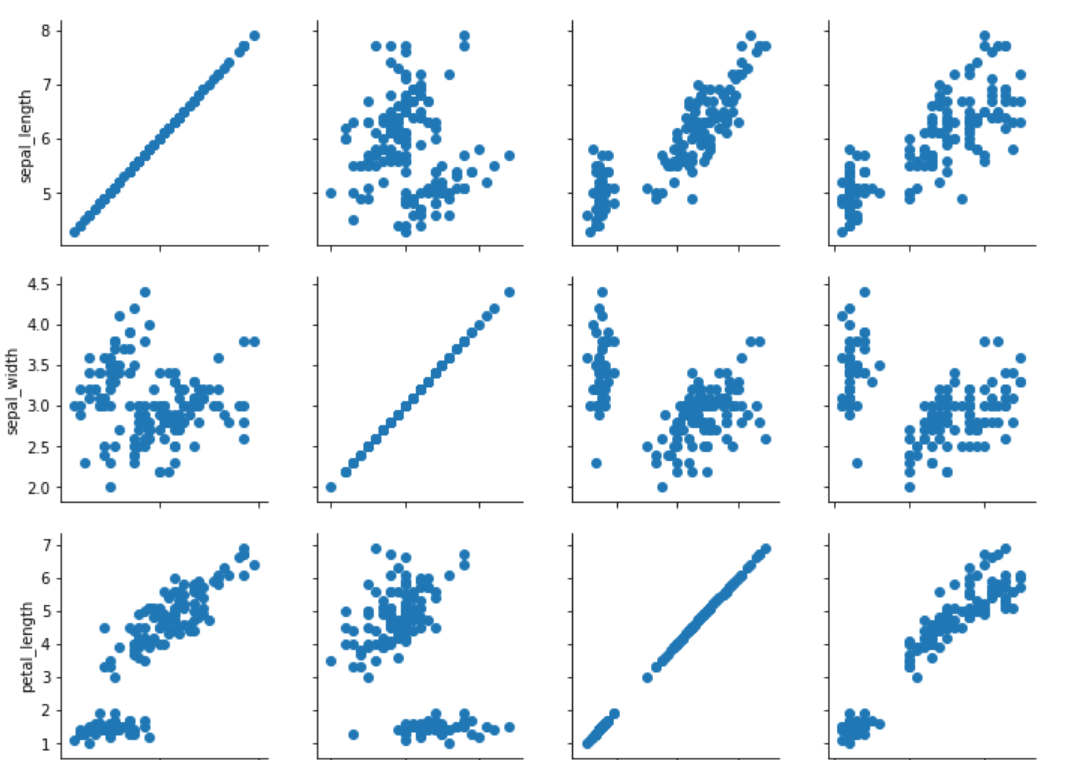
نمودارهای پراکندگی کلیه ترکیبات ستون های عددی در دادگان “iris” را می توانید مشاهده نمایید.
همچنین، انواع مختلف گراف ها را در یک شبکه جفتی می توان رسم کرد. مثلاً اگر خواهان رسم یک نمودار “توزیعی” در قطر، “kdeplot یا نمودار چگالی کرنل” در نیمه بالایی قطر و نمودار “پراکندگی” در نیمه پایینی قطر باشید، به ترتیب توابع map_digonal، map_upper و map_lower را می توانید مورد استفاده قرار دهید. نوع نموداری که باید رسم شود، به عنوان پارامتر، به این توابع ارسال می شود. نگاهی به اسکریپت زیر بیندازید:
grids = sns.PairGrid(dataset) grids.map_diag(sns.distplot) grids.map_upper(sns.kdeplot) grids.map_lower(plt.scatter)
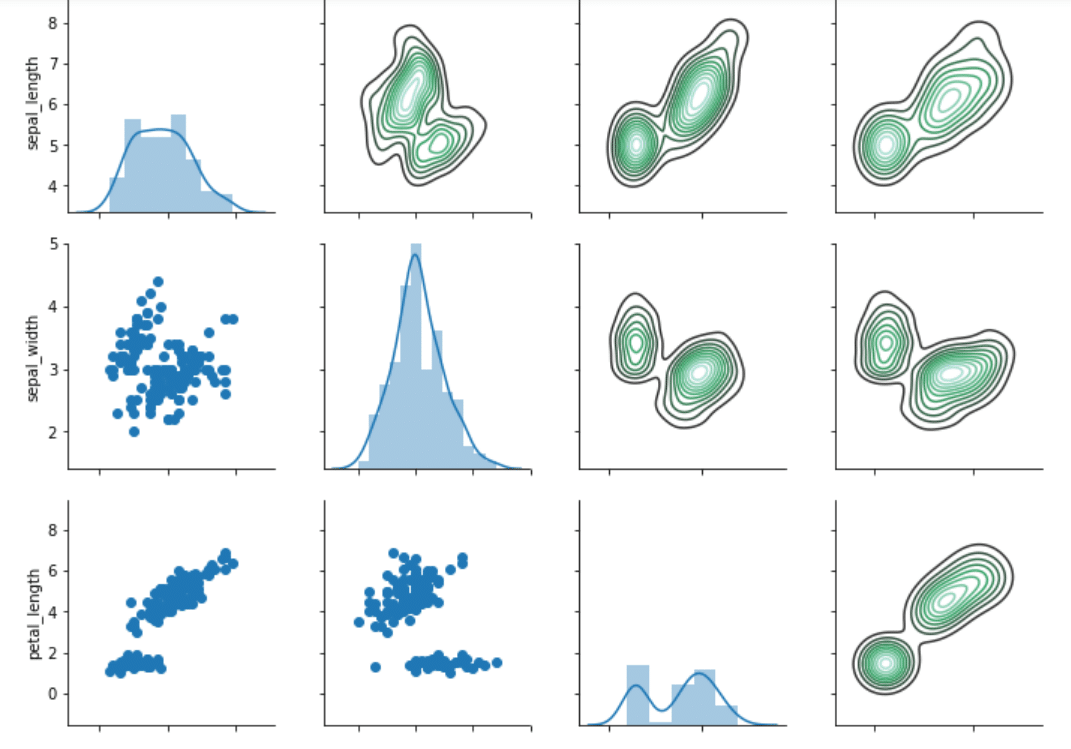
توان حقیقی تابع شبکه جفتی را در عکس بالا می توانید مشاهده نمایید. نمودارهای توزیعی را در قطرها، نمودارهای چگالی کرنل را در نیمه بالایی و نمودارهای پراکندگی را در نیمه پایینی داریم.
شبکه های چند وجهی (Facet Grids)
شبکه های چند وجهی، جهت رسم دو یا تعداد بیشتری از ویژگی های دسته ای نسبت به دو یا تعداد بیشتری از ویژگی های عددی مورد استفاده قرار می گیرند. حال بیایید یک شبکه چند وجهی را رسم نماییم که نمودار توزیعی جنسیت در مقایسه با افراد زنده مانده را با توجه به سن مسافران رسم می کند.
دادگان Titanic را به همین دلیل، مجدداً مورد استفاده قرار می دهیم. اسکریپت زیر را جهت بارگیری دادگان Titanic اجرا نمایید:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset = sns.load_dataset('titanic')تابع FacetGride برای رسم شبکه چند وجهی مورد استفاده قرار می گیرد. دادگان، پارامتر نخست این تابع است، پارامتر دوم col، نام داده ای که از آن برای ستون بندی نمودارها و پارامتر row، نام ویژگی که برای سطر بندی نمودارها استفاده میکند را مشخص می کند. تابع FacetGride، یک شیء (Object) را باز می گرداند. تابع map را همچون شبکه جفتی، برای مشخص نمودن نوع نموداری که می خواهید رسم کنید، می توانید بکار برید.
اسکریپت زیر را اجرا نمایید:
grid = sns.FacetGrid(data=dataset, col='alive', row='sex') grid.map(sns.distplot, 'age')
نمودار توزیعی سن در شبکه چند وجهی را در اسکریپت بالا رسم می کنیم. خروجی، چیزی شبیه مورد زیر است:
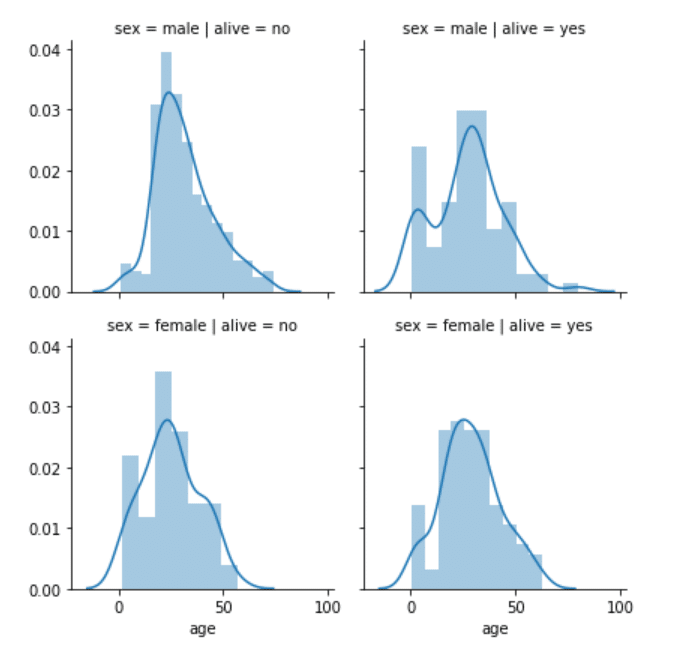
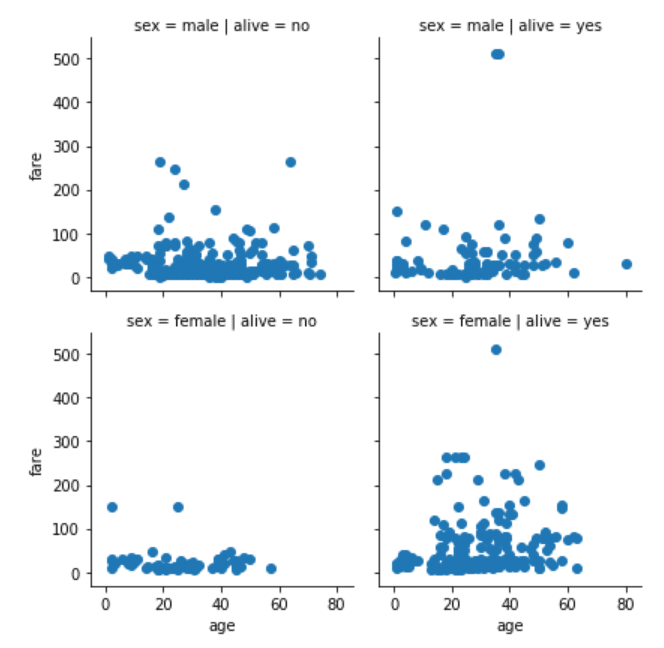
چهار نمودار را در خروجی می توانید مشاهده نمایید. هر کدام برای یک ترکیب جنسیت و زنده ماندن مسافران است. ستون ها و سطرها، همان طور که در تابع FacetGride مشخص ساختید، به ترتیب حاوی اطلاعاتی در رابطه با زنده ماندن و اطلاعات مربوط به جنسیت است.
سطر نخست و ستون نخست شامل توزیع سنی مسافرانی است که جنسیت شان، مذکر است و جان سالم بدر نبردند. سطر نخست و ستون دوم، توزیع سنی مسافرانی را در بر می گیرد که جنسیت شان، مذکر است و جان سالم بدر بردند. به همین ترتیب، سطر دوم و ستون نخست مشتمل بر توزیع سنی مسافرانی است که جنسیت آن ها، مونث است و جان سالم بدر نبردند، و در آخر سطر دوم و ستون دوم حاوی توزیع سنی مسافرانی است که جنسیت آنها، مونث است و زنده ماندند.
ما، علاوه بر استفاده از نمودارهای توزیعی برای یک ویژگی، نمودارهای پراکندگی را نیز مورد استفاده قرار می دهیم که دو ویژگی را در شبکه چند وجهی شامل می گردد.
برای نمونه، اسکریپت زیر، نمودار پراکندگی را برای سن و کرایه هر دو جنسیت مسافران زنده مانده و آنان که جان سالم بدر نبردند، رسم می کند.
grid = sns.FacetGrid(data= dataset, col= 'alive', row = 'sex') grid.map(plt.scatter, 'age', 'fare')
نمودار رگرسیونی
نمودارهای رگرسیونی، همان گونه که از نامشان بر می آید، جهت اجرای آنالیز رگرسیونی میان دو یا تعداد بیشتری متغیر مورد استفاده واقع می شوند.
نمودار مدل خطی را در این بخش مورد بررسی قرار خواهیم داد که رابطه خطی میان دو متغیر به همراه خط رگرسیون بهترین برازش (Best Fit Regression Line) بسته به داده را رسم می کند.
دادگان “diamonds” دادگانی است که قصد استفاده از آن را در این بخش داریم و به صورت پیش فرض، با استفاده از کتابخانه seaborn دانلود می شود. اسکریپت زیر را جهت بارگیری این دادگان اجرا نمایید:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
dataset = sns.load_dataset('diamonds')
dataset.head()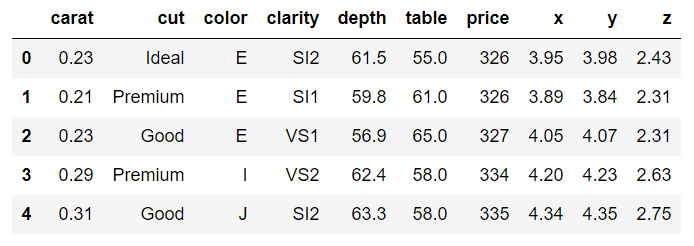
این دادگان حاوی ویژگی های مختلف یک الماس مانند وزن به قیراط، رنگ، شفافیت، قیمت و غیره است.
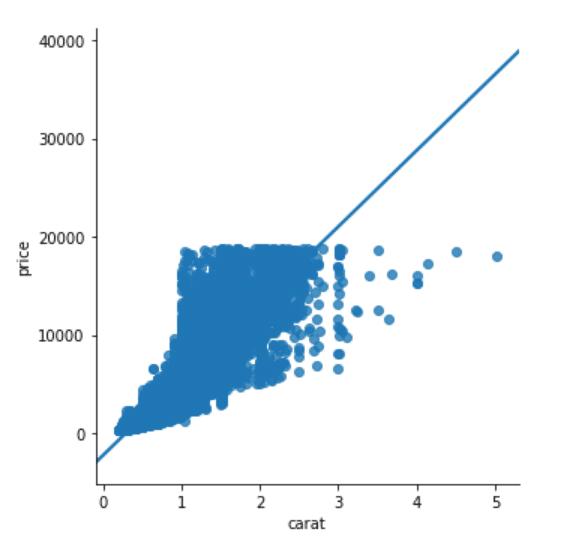
حال بیایید، رابطه خطی میان قیراط و قیمت الماس را رسم نماییم. مطلوب، این است که هرچه الماس، سنگین تر باشد، قیمتش می بایست بیشتر باشد. اینک بیایید ببینیم آیا این امر، بر اساس اطلاعات موجود در دادگان الماسها به راستی حقیقت دارد.
تابع lmplot، جهت رسم مدل خطی مورد استفاده قرار می گیرد. پارامتر نخست، آن ویژگی است که شما خواهان رسم آن در محور x هستید، و پارامتر دوم، به آن ویژگی اطلاق می گردد که می خواهید در محور y رسم نمایید. دادگان، پارامتر آخر را تشکیل می دهد. اسکریپت زیر را اجرا کنید:
sns.lmplot(x='carat', y='price', data=dataset)
در ضمن، مدل های خطی متعدد را بر اساس یک ویژگی دسته ای می توانید رسم نمایید. نام ویژگی، به عنوان مقدار، به پارامتر hue ارسال می گردد. مثلاً، چنانچه بخواهید نمودارهای خطی متعددی را برای رابطه میان قیراط و قیمت، بر اساس برش الماس، رسم کنید، تابع lmplot را به صورت زیر می توانید بکار برید:
sns.lmplot(x='carat', y='price', data=dataset, hue='cut')
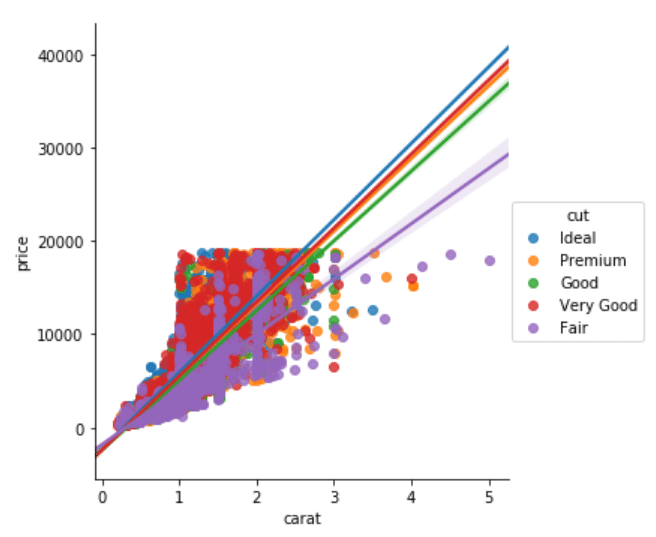
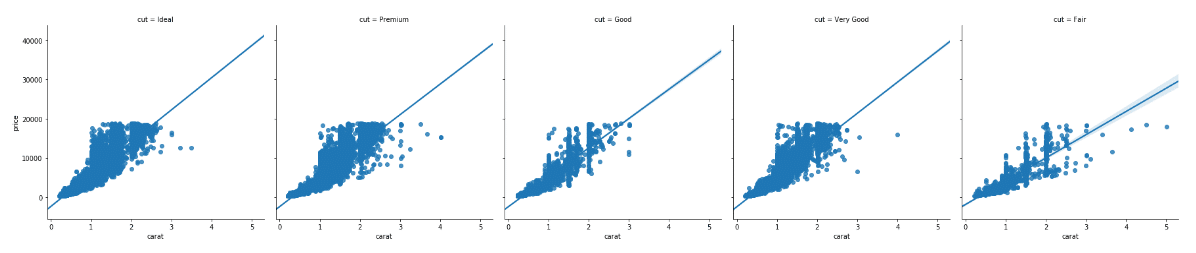
با توجه به خروجی می توان دریافت که رابطه خطی میان قیراط و قیمت الماس، همان طور که انتظار می رفت، دارای بیشترین شیب برای الماسِ با برش ideal است و مدل خطی، دارای کمترین شیب برای الماسِ با برش fair است. ما، علاوه بر رسم نمودار داده های ویژگی برش با استفاده از ویژگی hues، یک نمودار برای هر برش نیز می توانیم داشته باشیم. انجام این کار مستلزم ارسال نام ستون به ویژگی cols است. نگاهی به اسکریپت زیر بیندازید:
sns.lmplot(x='carat', y='price', data=dataset, col='cut')
یک ستون مجزا برای هر مقدار در ستون برش دادگان الماس ها را در خروجی مشاهده خواهید کرد که در قسمت زیر نشان داده می شود:
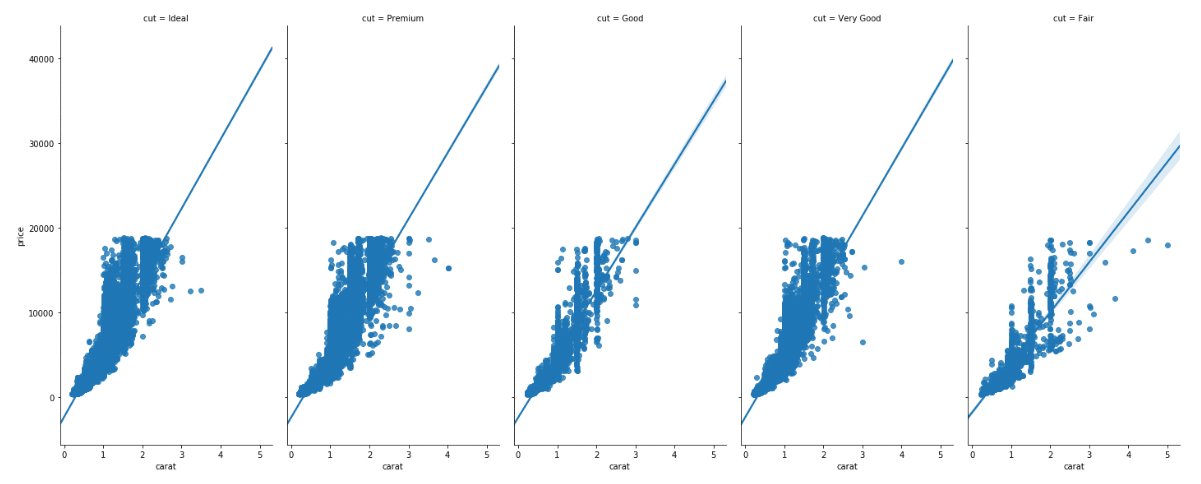
اندازه و نسبت نما (Aspect Ratio) نمودارها را نیز با استفاده از پارامترهای aspect و size می توانید تغییر دهید. نگاهی به اسکریپت زیر داشته باشید:
sns.lmplot(x='carat', y = 'price', data= dataset, col = 'cut', aspect = 0.5, size = 8 )
پارامتر aspect، نسبت نمای میان عرض و ارتفاع را تعریف می کند. یک نسبت نمای ۰.۵ بدان معناست که عرض، همان گونه که در خروجی نشان داده می شود، نصف ارتفاع است.
تغییر اندازه نمودار را می توانید به خوبی تشخیص دهید، اندازه فونت نیز بسیار کوچک است. نحوه کنترل فونت ها و استایل های نمودارهای Seaborn را در بخش بعد بررسی خواهیم کرد.
استایل نمودار
کتابخانه seaborn، انواع گزینه های استایل را ارائه می کند. برخی از آن ها را در این بخش بررسی خواهیم کرد.
تعیین استایل
تابع set_style، جهت تعیین استایل شبکه مورد استفاده قرار می گیرد. شما می توانید dargrid، whitegrid، dark، white و ticks را به عنوان پارامتر به تابع set_style ارسال نمایید.
“دادگان titanic” را در این بخش، مجدداً مورد استفاده قرار خواهیم داد. اسکریپت زیر را جهت مشاهده استایل darkgrid اجرا نمایید.
sns.set_style('darkgrid')
sns.distplot(dataset['fare'])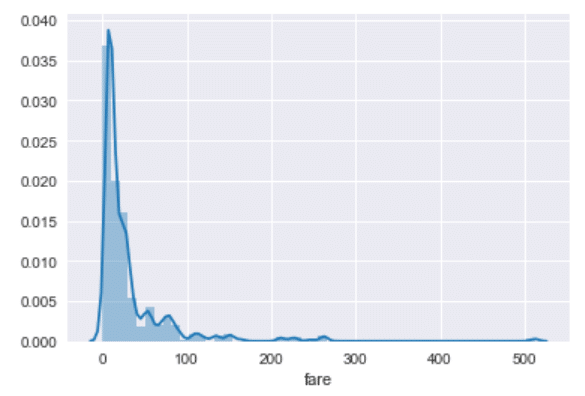
با توجه به خروجی در می یابید که پس زمینه تیره ی متشکل از شبکه ها را داریم. حال بیایید ببینیم که whitegrid چگونه به نظر می رسد. اسکریپت زیر را اجرا نمایید:
sns.set_style('whitegrid')
sns.distplot(dataset['fare'])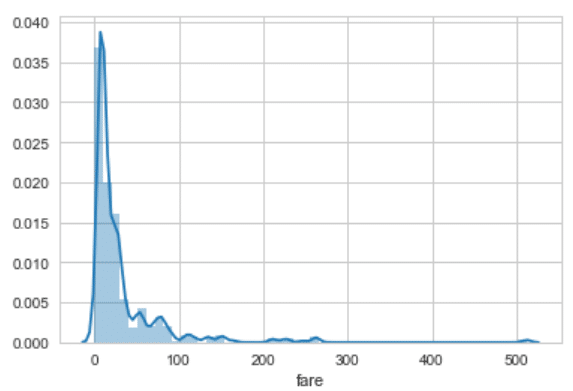
اینک در می یابید که همچنان شبکه هایی در پس زمینه تیره داریم، ولی پس زمینه خاکستری تیره، قابل رویت نیست. توصیه بنده بر این است که مابقی گزینه ها را امتحان کنید تا دریابید که استایل مناسب شما کدام است.
تغییر اندازه شکل
از آنجاییکه Seaborn، توابع Matplotlib پشت صحنه را مورد استفاده قرار می دهد، شما می توانید بسته pyplot متعلق به Matplotlib را جهت تغییر اندازه شکل، همانطور که در قسمت زیر نشان داده می شود، بکار برید:
plt.figure(figsize=(8,4)) sns.distplot(dataset['fare'])
عرض و ارتفاع نمودار را در اسکریپت بالا، به ترتیب 8 و 4 اینچ تعیین می کنیم. خروجی اسکریپت بالا، چیزی شبیه مورد زیر است:
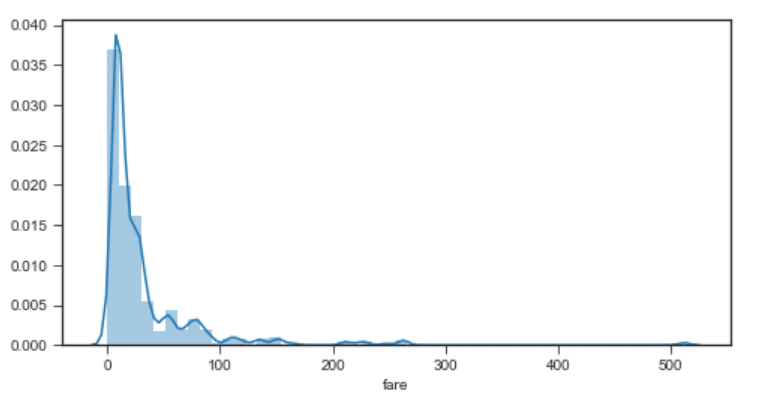
تعیین زمینه (Context)
ممکن است شما، جدای از نوت بوک، نمودارهایی برای پوسترها یا مقاله یا ارایه ایجاد نمایید. شما، برای انجام این کار، می توانید تابع set_context را مورد استفاده قرار دهید و poster را همان گونه در قسمت زیر نشان داده می شود، به عنوان تنها ویژگی، به آن ارسال نمایید. شما میتوانید از مقادیر paper, notebook, talk, poster در این تابع استفاده نمایید.
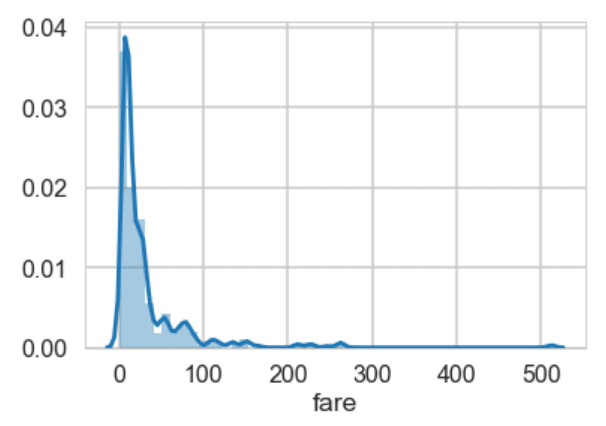
sns.set_context('poster')
sns.distplot(dataset['fare'])یک نمودار دارای خصوصیات پوستر را همانطور که در قسمت زیر نشان داده می شود، در خروجی می بایست ببینید. مثلا می توانید ببینید که فونت ها، در مقایسه با نمودارهای نرمال، بسیار بزرگ ترند.
نتیجه گیری
کتابخانه Seaborn، یک کتابخانه پیشرفته پایتون برای مصورسازی داده است. این مقاله، بخش سوم سری مقالات Seaborn مصورسازی داده در پایتون است. نحوه رسم نمودارهای رگرسیونی و ماتریسی در Seaborn را در این مقاله مورد بررسی قرار دادیم. درضمن، نحوه تغییر استایل های نمودار و استفاده از توابع شبکه ای برای دستکاری نمودارهای فرعی را بررسی نمودیم.